
Big Data
Big Data: Historia, usos y cómo aprovechar su potencial en empresas
En este artículo, exploraremos el origen y los estándares de esta revolución tecnológica en un mundo saturado de datos. La analogía humorística de Dan Ariely resalta la tendencia de usar términos de moda sin entender su verdadero significado, una práctica común en el mercado tecnológico. Mientras tanto, la explosión digital acelerada por la pandemia ha generado una cantidad masiva de información, pero Big Data va más allá de la simple acumulación de datos, se trata de cómo se emplea la información. Esta necesidad ha impulsado un mercado tecnológico en crecimiento que supera los 162.000 millones de dólares, evidenciando una revolución en desarrollo que requiere una comprensión clara de sus fundamentos.
¿Qué es Big Data y para qué sirve?
Para la firma analista Gartner, Big Data trata de activos de información de gran volumen, velocidad y variedad, que exigen formas rentables e innovadoras de procesamiento para mejorar la comprensión, la toma de decisiones y la automatización de procesos.
Big Data describe el gran volumen de datos –estructurados, semiestructurados y no estructurados– que inundan una empresa todos los días.
Lo realmente importante no es la cantidad de datos, sino cómo se usan. Big Data no busca acumular datos ni procesarlos; el fin último es generar insights, información relevante que ayude a la mejor toma de decisiones.
Big Data sirve para recopilar, procesar y analizar grandes cantidades de datos con el objetivo de obtener información valiosa. Facilita la identificación de patrones, tendencias y relaciones que respaldan la toma de decisiones informadas. Además, permite optimizar procesos, mejorar la eficiencia operativa y potenciar el rendimiento empresarial al proporcionar insights significativos basados en datos. En resumen, Big Data se utiliza para aprovechar el potencial de la información y obtener ventajas estratégicas en diversos ámbitos.
Para que el análisis de datos sea realmente útil, es crucial entender no solo qué es Big Data, sino también cómo utilizarlo estratégicamente en una organización. Conceptos como la analítica de datos, la inteligencia de negocios (BI) y el business analytics permiten transformar la información en decisiones de valor, gracias a herramientas y técnicas de análisis cada vez más sofisticadas.
Historia y evolución del Big Data
La popularización del término "Big Data" no se atribuye a un único individuo, sino que surgió como una respuesta a la creciente cantidad de información generada en la era de Internet. En los años 90, con el nacimiento de Internet y el advenimiento de la Web 2.0, el contenido en línea dejó de ser exclusivo de grandes empresas, permitiendo la participación masiva de usuarios en redes sociales y otros medios digitales.
Este fenómeno se vio potenciado por el surgimiento de smartphones y mejoras en redes móviles, lo que resultó en un explosivo aumento en la generación de datos. Para 2023, la cantidad de información generada a nivel mundial superó los 120 zettabytes, con un notable 90 % generado en los últimos 2 años.
Esta avalancha de datos planteó desafíos y oportunidades para las empresas. Por un lado, se enfrentaron al dilema de cómo gestionar y procesar tanta información, mientras que, por otro lado, reconocieron en estos datos una invaluable fuente para la toma de decisiones y la evolución hacia un modelo empresarial impulsado por datos.

Fuente: Statista
A medida que el volumen de datos crece, también lo hace la complejidad de su estructura. Herramientas como MySQL Workbench, tecnologías NoSQL y los RDBMS siguen siendo pilares en la gestión empresarial, permitiendo organizar tanto datos estructurados como semiestructurados con precisión y eficiencia.
Las 5 V de Big Data
Originalmente, en 2001, el analista de Gartner Doug Laney determinó 3 grandes V que definen al Big Data: Variedad, Volumen y Velocidad. Con el tiempo, esta definición se amplió hasta incluir dos más: Veracidad y Valor.
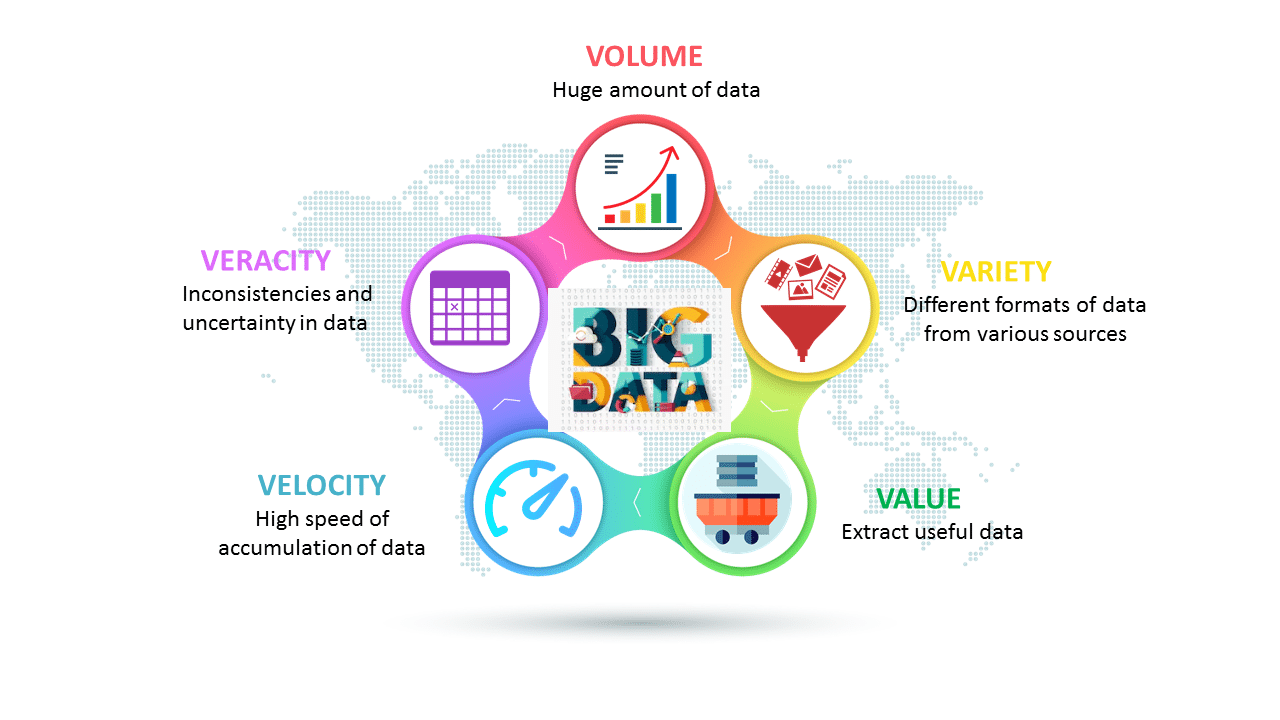
Fuente: Edureka
Para que unos datos sean considerados Big Data, deben cumplir con:
✔ Volumen: Gran cantidad de datos generados por dispositivos, redes y sensores.
✔ Variedad: Datos en múltiples formatos, como texto, imágenes, audio y video.
✔ Velocidad: Procesamiento en tiempo real para tomar decisiones instantáneas.
✔ Veracidad: Calidad y precisión de los datos para asegurar confiabilidad.
✔ Valor: Extraer insights significativos que generen impacto empresarial.
¿Cómo funciona Big Data?
El proceso de Big Data abarca varias etapas clave:
🔹 Recolección: Obtención de datos desde múltiples fuentes.
🔹 Almacenamiento: Uso de bases de datos y plataformas en la nube. El almacenamiento adecuado es clave para garantizar la escalabilidad y eficiencia del sistema de análisis. Tecnologías como los data lakes, los centros de datos empresariales y los sistemas de gestión de bases de datos permiten manejar grandes volúmenes de datos sin pérdidas ni sobrecostos, y aseguran una integración ágil con las plataformas de visualización y análisis.
🔹 Procesamiento: Aplicación de minería de datos y algoritmos de aprendizaje automático.
🔹 Análisis: Interpretación de datos para detectar patrones y tendencias.
🔹 Visualización: Representación gráfica para facilitar la toma de decisiones.
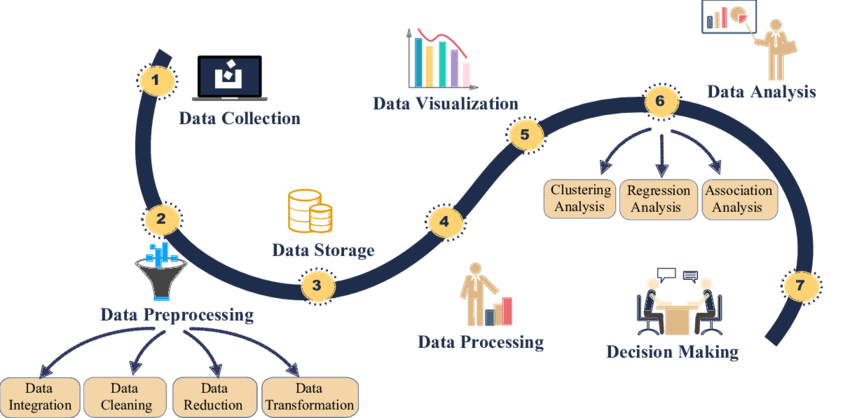
Fuente: ResearchGate
El verdadero poder del Big Data reside en su capacidad de generar valor tangible cuando se combina con herramientas analíticas, plataformas robustas y marcos estratégicos. Desde el procesamiento distribuido con Apache Hadoop hasta el uso de herramientas de análisis de datos para decisiones clave, el ecosistema actual exige una comprensión integral para convertir datos en impacto. Incluso áreas como la publicidad digital se benefician del análisis con métricas como el CPM, donde los datos guían cada decisión de inversión.














